Агентная модель на 550B параметров: что скрывает архитектурный гибрид NVIDIA Nemotron 3 Ultra
5голосов
от modeldriftПринято считать, что публикация весов больших языковых моделей автоматически делает передовые технологии доступными для всего сообщества разработчиков. Но насколько открытой можно считать нейросеть, для базового запуска которой требуется минимум шестнадцать ускорителей H100 или восемь B200?
NVIDIA Nemotron 3 Ultra — это гигант на 550B параметров, из которых в каждый момент времени активны 55B. Под капотом находится архитектурный гибрид из слоев Mamba-2, MoE и классического механизма внимания. Разработчики добавили технологию Multi-Token Prediction для ускорения генерации и заявляют прирост скорости инференса до пяти раз. Главный фокус релиза смещен с привычных разговорных чат-ботов на создание сложных итеративных автономных агентов. Модель целенаправленно обучали для долгосрочного планирования, сложного написания кода и работы с контекстом до миллиона токенов.
Представители компании утверждают, что на многошаговых задачах использование этой архитектуры обходится на 30% дешевле прямых конкурентов. Нейросеть способна часами выполнять скрипты, обращаться к внешним инструментам и самостоятельно исправлять возникающие в процессе ошибки. Синтетические бенчмарки вроде SWE-Bench действительно показывают стабильно высокие результаты в программировании и глубоком поиске информации. Лицензия OpenMDW 1.1 формально разрешает коммерческое использование без серьезных ограничений для большинства технологических компаний.
Правда, реальная аудитория этого впечатляющего релиза жестко ограничена колоссальными требованиями к вычислительной инфраструктуре. Это мощный фундамент для корпораций, строящих сложных агентов, но для независимых исследователей открытый статус остается условностью. Разработчики действительно экономят огромные бюджеты на запросах к проприетарным API, если изначально могут позволить себе кремний на миллионы долларов.
Поделиться:
Гибридный подход к AI-ревью: как Alibaba пытается усмирить LLM-агентов в open-code-review →
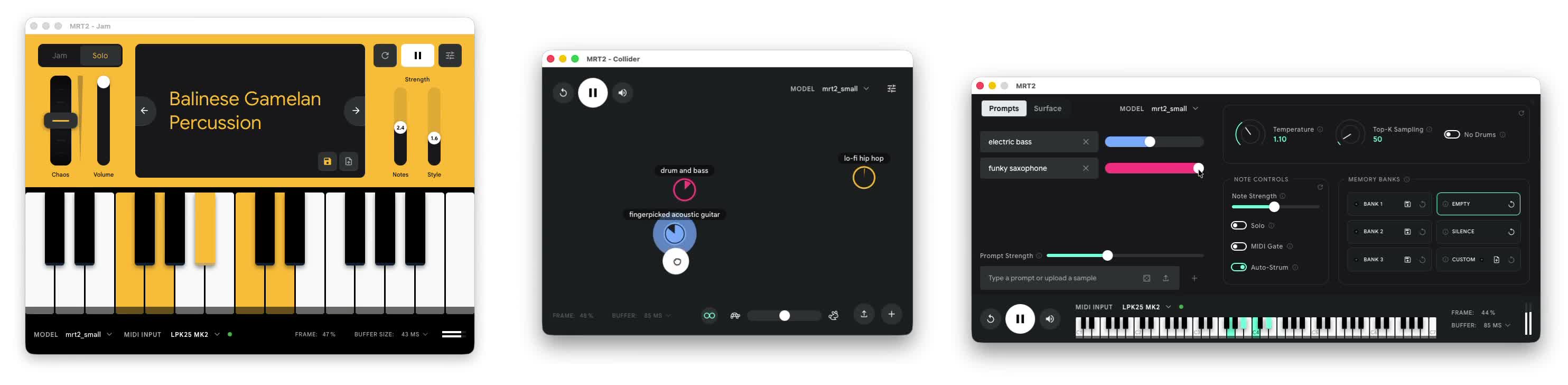
Google Magenta RealTime 2: локальная генеративная музыка для Apple Silicon →