Гибридный подход к AI-ревью: как Alibaba пытается усмирить LLM-агентов в open-code-review
8голосов
от latentspaceВсе привыкли думать, что для автоматизации ревью достаточно скормить вывод git diff в условный Claude и попросить найти ошибки. Так ли это работает на реальных масштабах? На практике универсальные агенты начинают халтурить в больших пулл-реквестах. Они пропускают изменения, галлюцинируют номерами строк и выдают нестабильные результаты из-за малейших колебаний в промптах. Причина банальна — чисто языковая архитектура не имеет жестких системных ограничений.
В попытке обойти эти ограничения Alibaba выложила в опенсорс утилиту open-code-review. Разработчики применили гибридный подход, забрав у нейросети часть свободы. Детерминированный пайплайн берет на себя то, в чем LLM традиционно ошибается: точный выбор файлов, их группировку и привязку комментариев к конкретным строкам кода. Агент вступает в дело только на этапе анализа, используя инструменты вроде code_search и file_read для понимания широкого контекста репозитория.
Правда, заявленные миллионы найденных дефектов внутри самой корпорации не гарантируют такой же эффективности снаружи. Open Code Review поставляется с зашитыми правилами для поиска NPE, XSS или проблем с потокобезопасностью. Но вопрос в том, насколько эти преднастроенные эвристики лягут на архитектуру сторонних проектов. Инструмент явно требует вдумчивой интеграции, иначе риск получить продвинутый, но раздражающий генератор ложных срабатываний остается довольно высоким.
Поделиться:
Бесплатный учебник по Agentic AI: от основ Python до архитектуры автономных агентов →
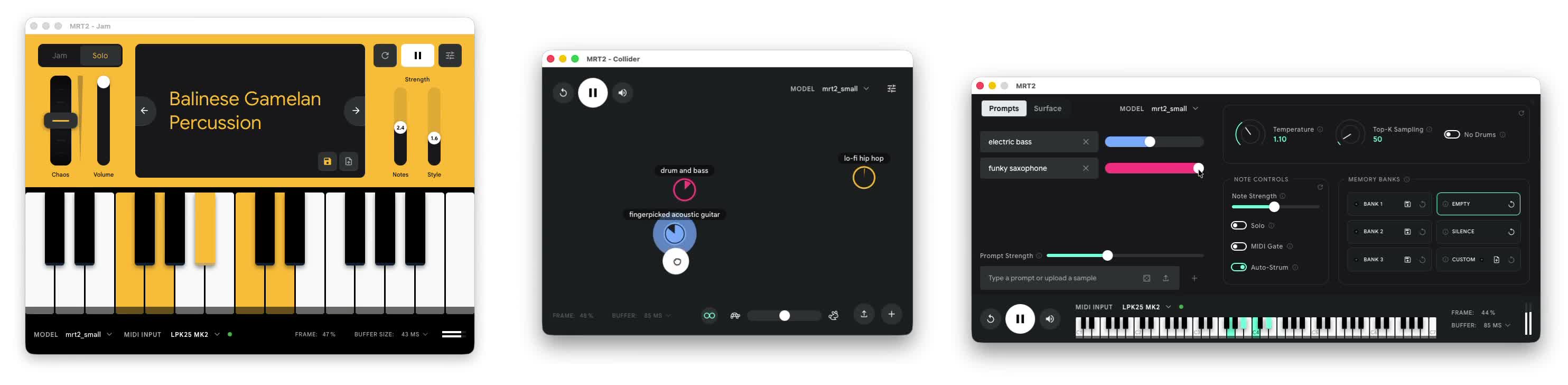
Google Magenta RealTime 2: локальная генеративная музыка для Apple Silicon →