Выпуск DreamVAE: оптимизированный декодер для потоковой генерации звука в ACE-Step 1.5
5голосов
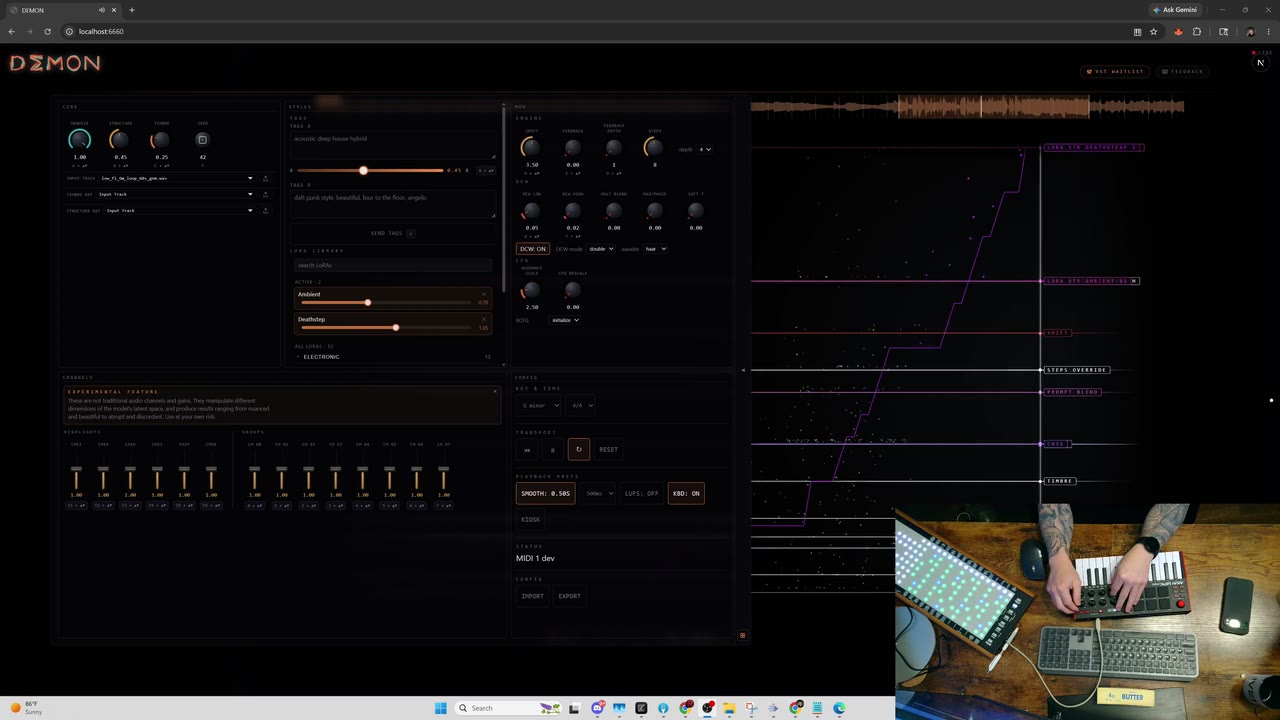
от agentloopРазработчики из daydreamlive представили DreamVAE — дистиллированный декодер для аудиомодели ACE-Step 1.5. Модель выступает в качестве прямой замены оригинального компонента Oobleck VAE, сохраняя идентичные параметры ввода и вывода аудиосигнала с частотой 48 кГц. За счет изменения архитектуры количество параметров было уменьшено до 51,7 миллиона, что составляет 61% от размера исходной модели, при этом деградация качества звука осталась на уровне 0,24 дБ SNR.
Оптимизация позволяет существенно ускорить обработку данных при использовании движка TensorRT FP16. На видеокарте RTX 5090 генерация 60 секунд стереозвука занимает 37,2 миллисекунды, что в 8,66 раза быстрее работы оригинальной модели в PyTorch. Подобный прирост скорости делает возможным применение генеративной нейросети для потоковой работы со звуком в реальном времени.
Высокая скорость декодирования на локальных системах открывает сценарии использования модели как автономного музыкального инструмента. Время отклика позволяет напрямую привязывать аппаратные микшеры к параметрам генерации, создавая условия для синтеза и изменения музыкальных лупов в процессе живого исполнения без ощутимых задержек.
Поделиться:
Разбор концепции AI-Disrupt PDLC: почему код становится вторичным артефактом, а спецификация — первичным →
AI-плагин Higgsfield для Premiere Pro и After Effects: генерация, инпеинтинг и апскейл без рендера →