Аудио-LoRA на Civitai: модульная генерация музыки в модели ACE Audio на базе синтетических датасетов
4голоса
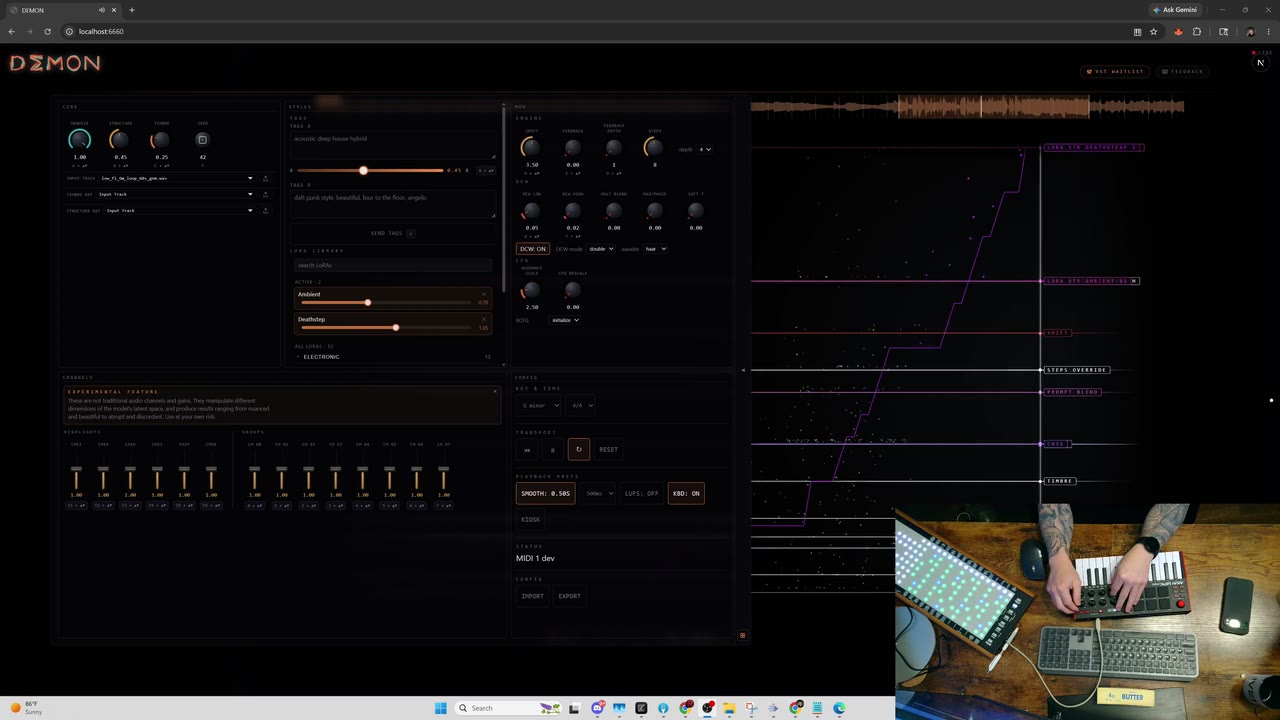
от latentspaceЭкосистема генеративного аудио начинает копировать успешные пайплайны из работы с визуальными нейросетями. На Civitai опубликовали набор экспериментальных ACEStep LoRAs — это веса для базовой модели ACE Audio, заточенные под генерацию конкретных музыкальных жанров от фонка до дип-хауса. Главная деталь релиза: весь тренировочный датасет был полностью синтетическим.
Автор сборки под ником ryanontheinside спроектировал эти LoRA для живого ремикширования в среде DEMON. Использование сгенерированных звуковых паттернов вместо лицензионных треков для файнтюнинга обходит вопросы авторского права при копировании стиля. Для локального запуска требуется базовый чекпоинт phonk-v1 и приложенный JSON-файл с метаданными.
Инфраструктура для пользовательских аудиомоделей пока только формируется. В репозитории прямо сейчас стабильно отдается только модуль PHONK_A, а парсинг конфигураций периодически выдает ошибки формата. Однако появление аудио-LoRA на исторически визуальной платформе фиксирует технический сдвиг: модульная стилизация с помощью легковесных адаптеров становится стандартом и для программного саунд-дизайна.
Поделиться:
Разбор концепции AI-Disrupt PDLC: почему код становится вторичным артефактом, а спецификация — первичным →
AI-плагин Higgsfield для Premiere Pro и After Effects: генерация, инпеинтинг и апскейл без рендера →