Как работает живая генерация звука на базе ACEStep1.5 и аппаратных контроллеров
7голосов
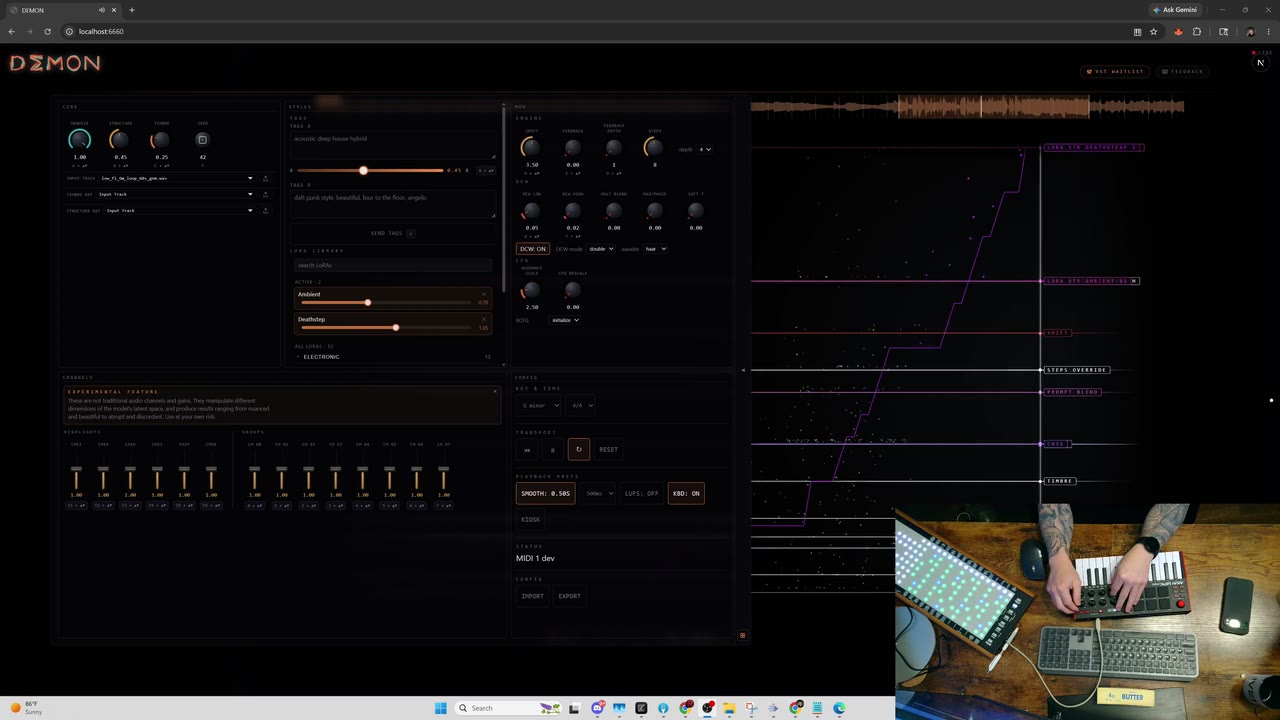
от inferenceonlyГенерация аудио тихо переходит из формата оффлайн-рендера в лайв-инструменты. Разработчики собрали сетап, который работает как Stream Diffusion, но для звука — процессом теперь управляют через физические MIDI-контроллеры.
В основе проекта лежит опенсорсная архитектура ACEStep1.5. Движок запускается локально на картах уровня RTX 3090 или 4090, а аппаратные фейдеры напрямую меняют параметры инференса. Такой подход убирает задержку между вводом и результатом: генеративная модель ведет себя как классический хардверный синтезатор для создания лупов и ремиксов в реальном времени.
Базовое звучание можно переключать прямо на лету. Для этого автор проекта выложил пакет экспериментальных LoRA, заточенных под лайв-интерфейс DEMON. Доступны веса для жанров Phonk, Deephouse, Ambient и Deathstep, натренированные на синтетических датасетах. Важная техническая деталь: для корректного инференса каждого .safetensors чекпоинта требуется положить рядом оригинальный .json конфиг, иначе движок не подхватит метаданные при живом сведении.
Поделиться:
Разбор концепции AI-Disrupt PDLC: почему код становится вторичным артефактом, а спецификация — первичным →
AI-плагин Higgsfield для Premiere Pro и After Effects: генерация, инпеинтинг и апскейл без рендера →