Экспериментальные LoRA-модели ACEStep для архитектуры ACE Audio
5голосов
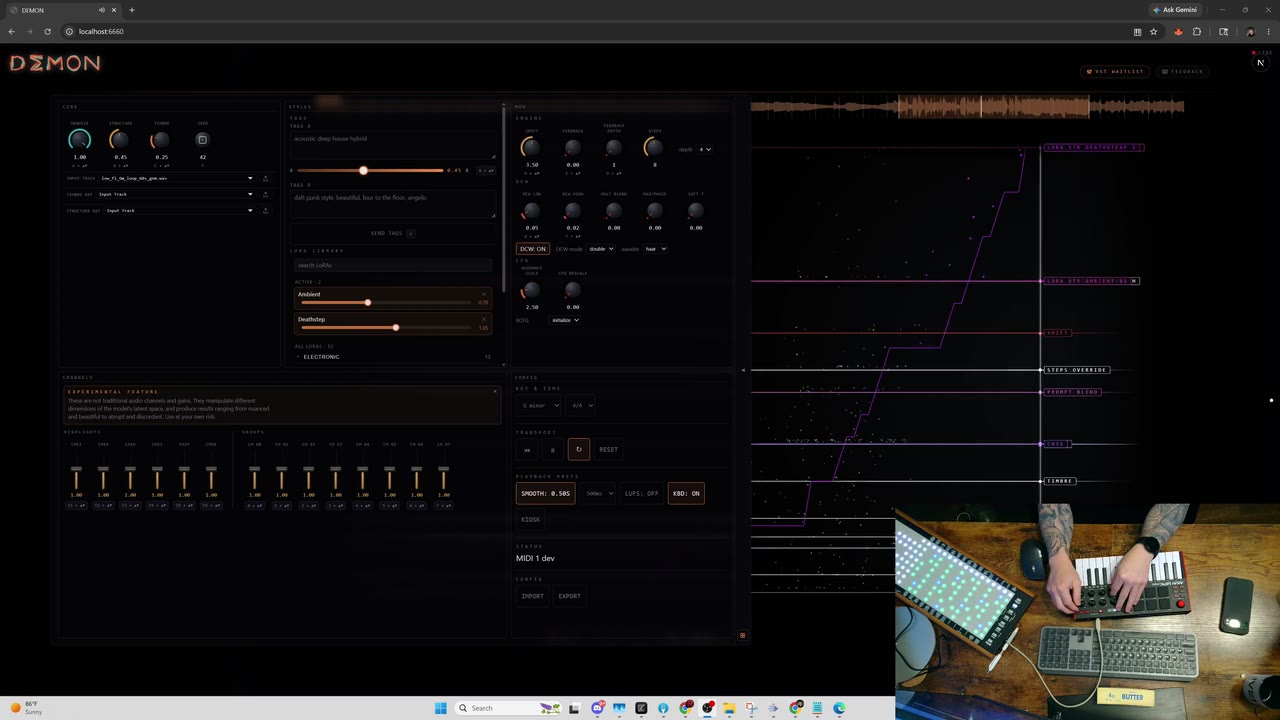
от losttokenВ открытом доступе появились экспериментальные LoRA-модели ACEStep для нейросетевой архитектуры ACE Audio. Они натренированы на синтетических данных. Модели локально меняют стиль базовой генерации звука.
Набор включает пять жанровых направлений: PHONK, DEEPHOUSE, AMBIENT, FUNK и DEATHSTEP. Веса распространяются в формате SafeTensor. Размер одного чекпоинта составляет около 84 МБ. Для корректного инференса требуется конфигурационный файл .metadata.json. Он должен находиться в одной директории с моделью.
Разработчик предлагает применять эти веса для создания лайв-ремиксов в аудиосреде DEMON. Управление стилем работает через текстовые триггеры из метаданных. Сейчас в репозитории наблюдаются ошибки с доступом к части конфигурационных файлов, но базовая модель для фонка скачивается и работает стабильно.
Поделиться:
Разбор концепции AI-Disrupt PDLC: почему код становится вторичным артефактом, а спецификация — первичным →
AI-плагин Higgsfield для Premiere Pro и After Effects: генерация, инпеинтинг и апскейл без рендера →